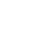将激活、权重和梯度量化为4位,有望加速神经网络训练。
然而,现有的4位训练方法需要自定义数字格式,而现代硬件不支持这种格式。
最近,清华朱军团队提出了一种使用INT4算法实现所有矩阵乘法的Transformer训练方法。
使用超低INT4精度进行训练,是非常具有挑战性的。为了实现这一目标,研究者仔细分析了Transformer中激活和梯度的具体结构,为它们提出专用的量化器。
对于前向传播,研究者确定了异常值的挑战,并提出了Hadamard量化器来抑制异常值。
对于后向传播,他们通过提出位分割,来利用梯度的结构稀疏性,并利用分数采样技术来准确量化梯度。
这种新的算法,在自然语言理解、机器翻译和图像分类等广泛任务上,都实现了具有竞争力的准确性。
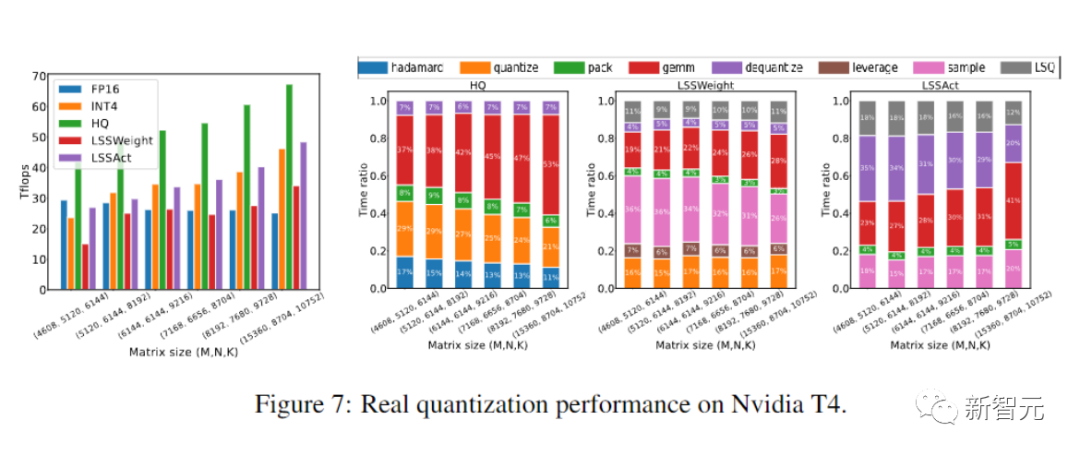
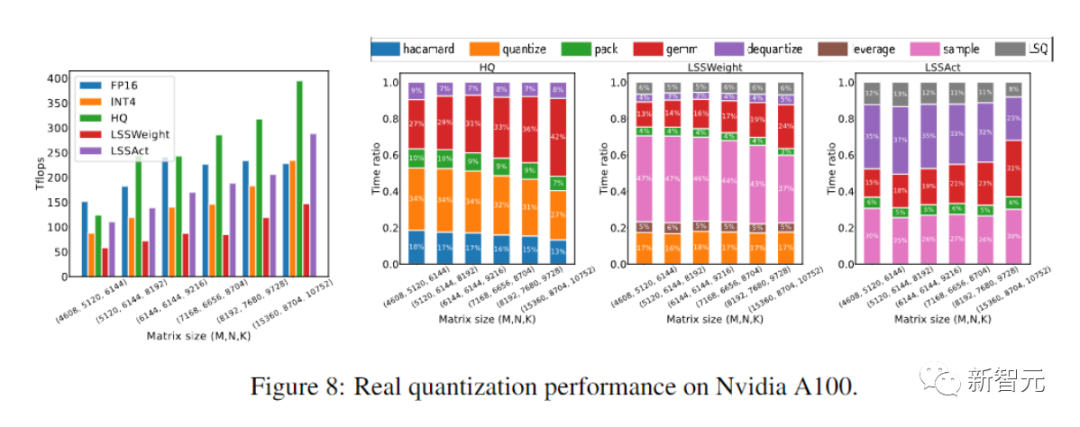
原型线性算子运算速度比FP16同类算子快2.2倍,训练速度提高了35.1%。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 图片
图片
论文地址:https://arxiv.org/abs/2306.11987
代码地址:https://github.com/xijiu9/Train_Transformers_with_INT4
全新的INT 4训练算法
训练神经网络对计算的要求很高。使用低精度算术进行训练(完全量化训练/FQT)有望提高计算和内存效率。
FQT方法在原来的全精度计算图中添加了一些量化器和反量化器,并用消耗更小的低精度浮点运算,代替了消耗更高的浮点运算。
FQT的研究旨在降低训练数值精度,而不牺牲太多的收敛速度或精度。
所需的数值精度已从FP16降低到FP8、INT32+INT8和INT8+INT5。
FP8训练是在带有Transformer引擎的Nvidia H100 GPU中实现的,加速了大规模Transformer的训练。最近的训练数值精度,已经降到了4位。
然而,这些4位训练方法不能直接用于加速,因为它们需要自定义数字格式,而现代硬件不支持这些格式。
首先,前向传播中的不可微量化器,会使损失情况变得崎岖不平,基于梯度的优化器很容易陷入局部最优。
其次,梯度仅仅以低精度近似计算。这种不精确的梯度会减慢训练过程,甚至导致训练不稳定或发散。
而在这项工作中,研究者为Transformer提出了一种新颖的INT4训练算法。
 图片
图片
训练Transformer的所有高消耗的线性运算,都可以写在矩阵乘法(MM)的形式中。
这种MM形式,可以让我们设计更灵活的量化器,通过利用Transformer中激活、权重和梯度的特定结构,就可以更好地近似于FP32矩阵乘法。
随机数值线性代数 (RandNLA) 领域的进步,被这种量化器充分利用。
对于前向传播,研究者发现,激活中的异常值是精度下降的主要原因。
为了抑制异常值,他们提出了Hadamard量化器,它会对激活矩阵的变换版本进行量化。这种变换是块对角Hadamard矩阵,它将离群值中携带的信息传播到矩阵的邻近条目,从而缩小了离群值的数值范围。
对于后向传播,他们利用了激活梯度的结构稀疏性。研究者发现,一些token的梯度非常大。同时,其余大多数token的梯度非常均匀,甚至比较大梯度的量化残差更均匀。
 图片
图片
因此,与其计算所有梯度,不如节省计算较大梯度残差的计算资源。
为了利用这种稀疏性,研究者提出了位分割,将每个token的梯度分割为高4位和低4位。
然后,通过杠杆分数采样(leverage score sampling)来选择信息最丰富的梯度,这是RandNLA的一种重要采样技术。
 图片
图片
结合前向和后向传播的量化技术,研究者提出了一种使用INT4MM进行Transformer中所有线性运算的算法, 并且评估了在各种任务上训练Transformer的算法,包括自然语言理解、问答、机器翻译和图像分类。
与现有的4位训练算法相比,他们的算法实现了有竞争力的或更高的精度。
此外,这种算法与GPU等当代硬件兼容,因为它不需要FP4或对数格式等自定义的数字格式。
这种原型量化+INT4 MM算子实现,速度比FP16MM基线快2.2倍,并且将训练速度提高了35.1%。
相关工作
完全量化训练
完全量化训练 (FQT) 方法通过将激活、权重和梯度量化为低精度来加速训练,因此训练期间的线性和非线性算子可以用低精度算术来实现。
FQT的研究设计了新颖的数值格式和量化算法,可以更好地逼近全精度张量。
目前的研究前沿是4位FQT。由于梯度的数值范围很大以及从头开始训练量化网络的优化问题,FQT具有挑战性。
由于这些挑战,现有的4位FQT 算法在某些任务上的精度仍然下降了1-2.5%,并且无法支持当代硬件。
 图片
图片
其他有效的训练方法
混合专家在不增加训练预算的情况下提高了模型容量。
结构性dropout利用计算有效的方法来正则化模型。高效的注意力降低了计算注意力的二次时间复杂度。
分布式训练系统通过利用更多的计算资源,减少了训练时间。
研究者降低数值精度的工作与这些方向具有正交性。
 图片
图片
前向传播
神经网络训练是一个迭代优化过程,通过前向和后向传播计算随机梯度。
研究团队使用4位整数(INT4)算法加速前向和后向传播。
正向传播能以线性和非线性(GeLU, normalization, softmax等)算子的组合来实现。
在我们的训练过程中,我们用INT4算术加速所有线性运算符,并将所有计算量较小的非线性运算符保留在16位浮 点(FP16)格式中。
Transformer中的所有线性运算都可以写成矩阵乘法(MM)的形式。
为了便于表述,本文考虑以下简单矩阵乘法的加速:
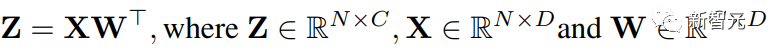 图片
图片
这种MM的最主要用例是全连接层。
考虑一个输入形状为(批量大小S,序列长度T,维度D)的Transformer。
全连接层可以表述成上边的公式,其中X是N = STtoken的激活,W是权重矩阵。
对于注意力层,可能需要批量矩阵乘法(BMMS)。
我们提出的技术可以应用于BMMS。
学习步长量化(Learned Step Quantization)
为了加速训练,必须使用整数运算来计算前向传播。
研究人员为此目的,利用学习步长量化器(LSQ)。
LSQ是静态量化,他的量化尺度不依赖于输入的方法,因此比动态方法消耗更小,量化方法,需要在每次迭代时动态计算量化尺度。
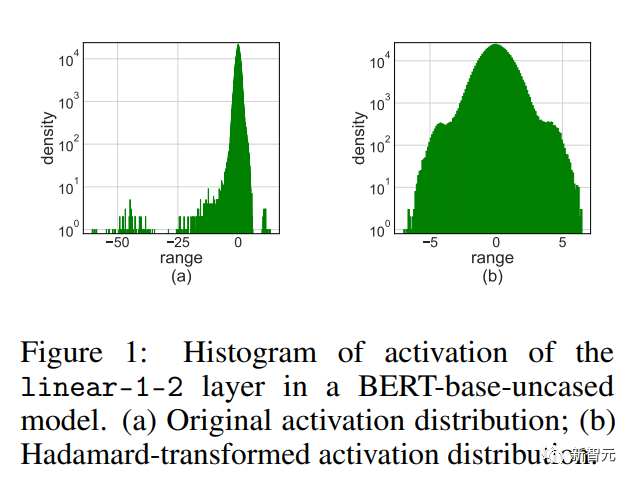
激活异常值
简单地将LSQ应用到具有4位激活/权重的FQT会导致精度下降,因为会激活异常值。
 图片
图片
如上图所示,激活有一些离群值条目,它们是其规模比其他条目大得多。
不幸的是,Transformers倾向于将信息存储在这些异常值中,而且这样的截断会严重损害准确性。
当训练任务是在一些新的下游任务上微调预训练模型时,异常值问题尤为明显。
因为预训练模型比随机初始化包含更多的异常值 。
Hadamard量化
我们提出了Hadamard量化(HQ)来解决异常值问题。
其主要思想是将另一个具有较少异常值的线性空间中的矩阵进行量化。
激活矩阵中的异常值形成了一个特征结构(feature-wise structure)。
他们通常集中在几个维度上,也就是说X中只有几列显著大于其他列。
哈达玛变换(Hardamand transform)是一个线性变换,它可以将异常值分摊到其他条目中。
后向传播
现在我们考虑使用INT4操作来加速线性层的后向传播。
我们将在本节中讨论激活梯度/权重梯度的计算。
梯度的结构稀疏性
我们注意到,在训练过程中梯度矩阵往往非常稀疏。
而且稀疏性具有这样的结构:
 的几行(比如tokens)具有较大的条目,而大多数其他行却接近全零向量。
的几行(比如tokens)具有较大的条目,而大多数其他行却接近全零向量。
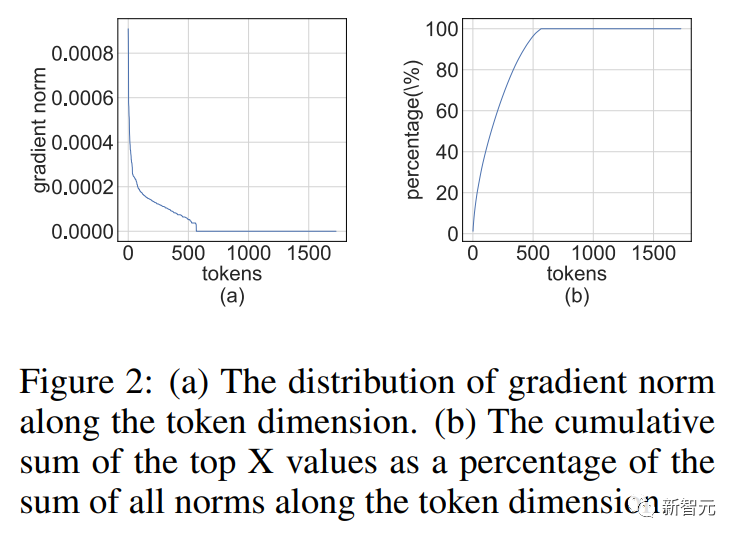 图片
图片
这种结构稀疏性源于现代神经网络的严重过度参数化。
几乎在整个训练过程中,网络都以超参数化方案运行,除了一些困难的例子之外,它可以很好地适应大多数训练数据。
因此,对于拟合良好的数据点,(激活)梯度将接近于零。
研究人员发现对于预训练任务,例如,经过几个训练周期后,结构稀疏性很快就会出现。
对于微调任务,梯度整个训练过程中始终是稀疏的。
位分割(Bit Splitting)和杠杆分数采样(Leverage Score Sam pling)
pling)
 pling)
pling)如何设计梯度量化器,以利用结构稀疏性在反向传播期间准确计算MM呢?
高级的思路是:梯度的许多行都是如此小,对参数梯度影响很小,但浪费了大量的计算量。
另一方面,大行无法用INT4精确表示。
我们放弃掉一些小行并使用节省下来的计算能力来更准确地表示大行。
实验
 ChatGPT Writer
ChatGPT Writer
免费 Chrome 扩展程序,使用 ChatGPT AI 生成电子邮件和消息。
 106
查看详情
106
查看详情

研究人员在包括语言模型在内的各种任务上评估我们的INT4训练算法微调、机器翻译和图像分类。
研究人员用CUDA和cutlass执行了他们提出的HQ-MM和LSS-MM算法。
研究人员用INT4实现替换所有浮点线性运算符,但没有简单地使用LSQ来嵌入层,并保持最后一个分类器层的精度。
最后研究人员对所有评估的模型采用了默认架构、优化器、调度器和超参数。
收敛模型精度
研究人员在下表中比较了收敛模型在各种任务上的准确性。
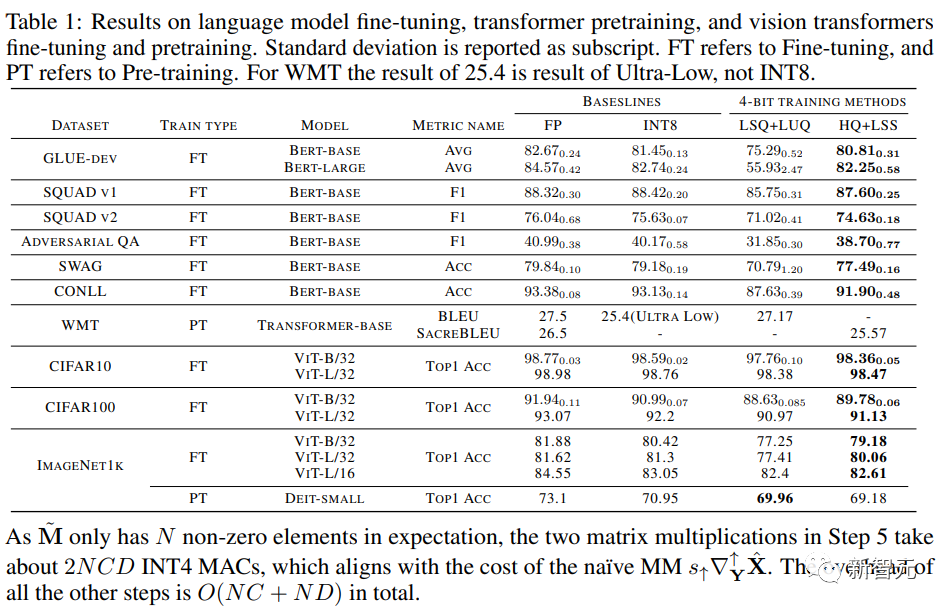 图片
图片
作为对照的方法包括全精度训练(FP)、INT8训练(INT8)、FP4训练(「超低」),使用LSQ进行激活和权重(LSQ+LUQ)的4 位对数量化,以及我们这种利用HQ进行前向传播,利用LSS进行反向传播(HQ+LSS)的算法。
「超低」没有公开的实现,因此我们仅列出了它在机器上的原始论文中的性能翻译任务。
除了大型机器翻译任务和大型视觉Transformer任务之外,我们将每次运行重复三次,并将标准差报告为表中的下标。
研究人员没有进行任何类型的知识蒸馏或数据增强。
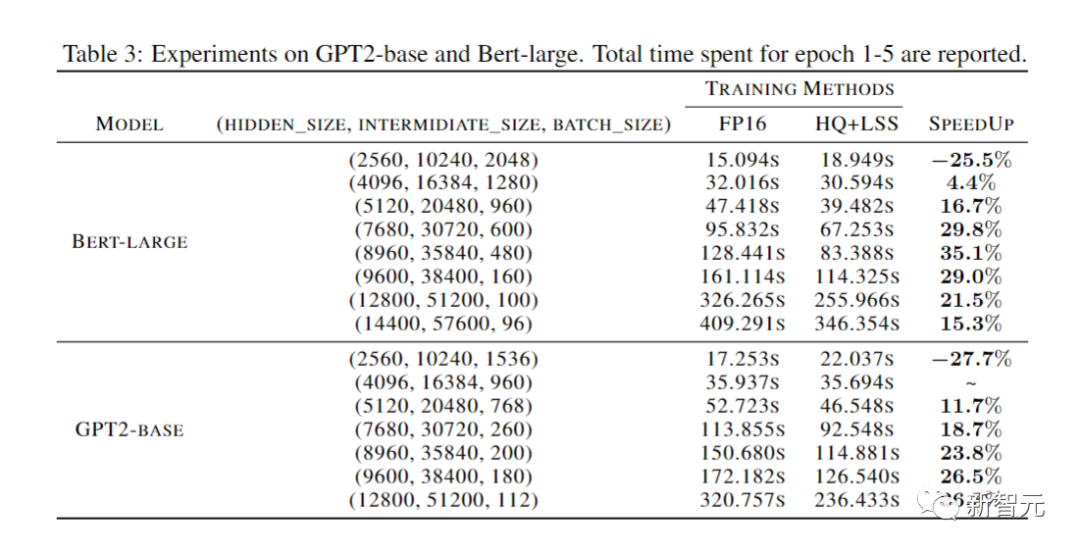
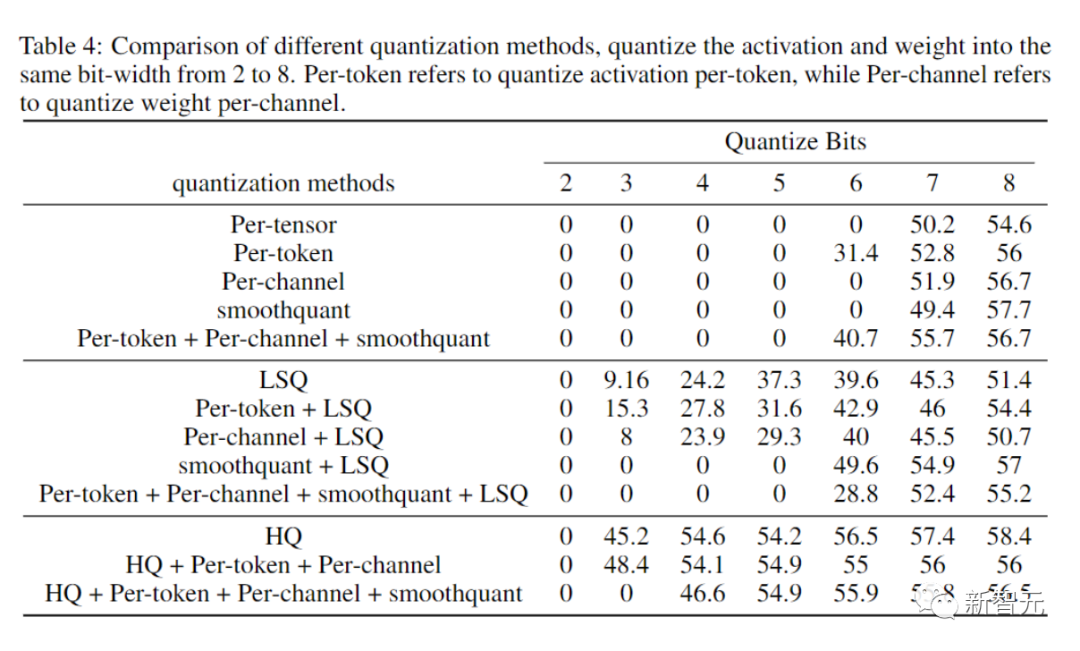
消融实验
研究人员进行的消融实验目的是展示前向和后向方法的有效性。
研究不同量化器的前向传播的有效性,我们将后向传播留在FP16中。
结果如下图所示。
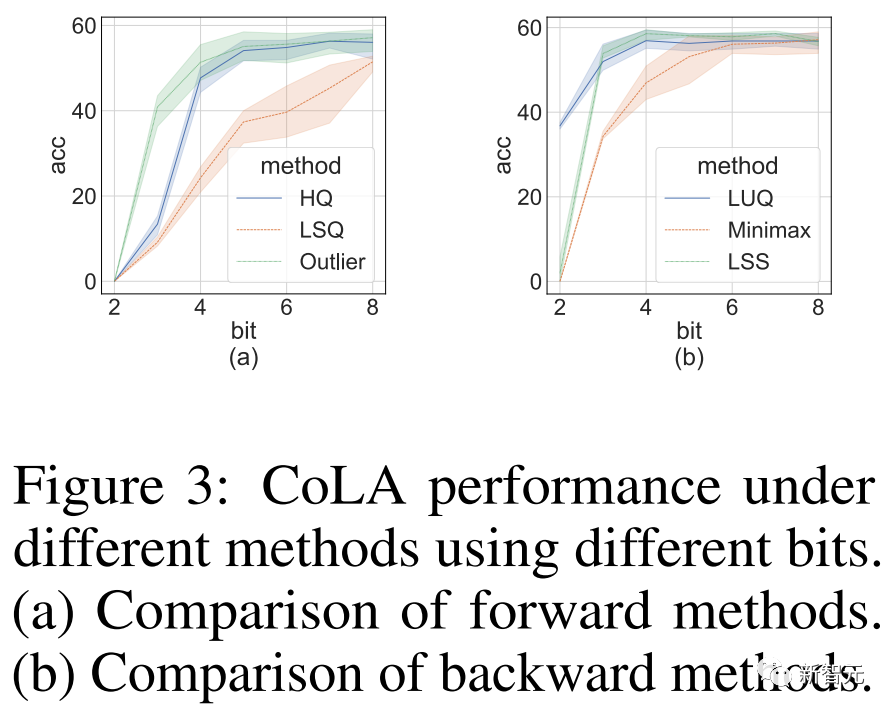 图片
图片
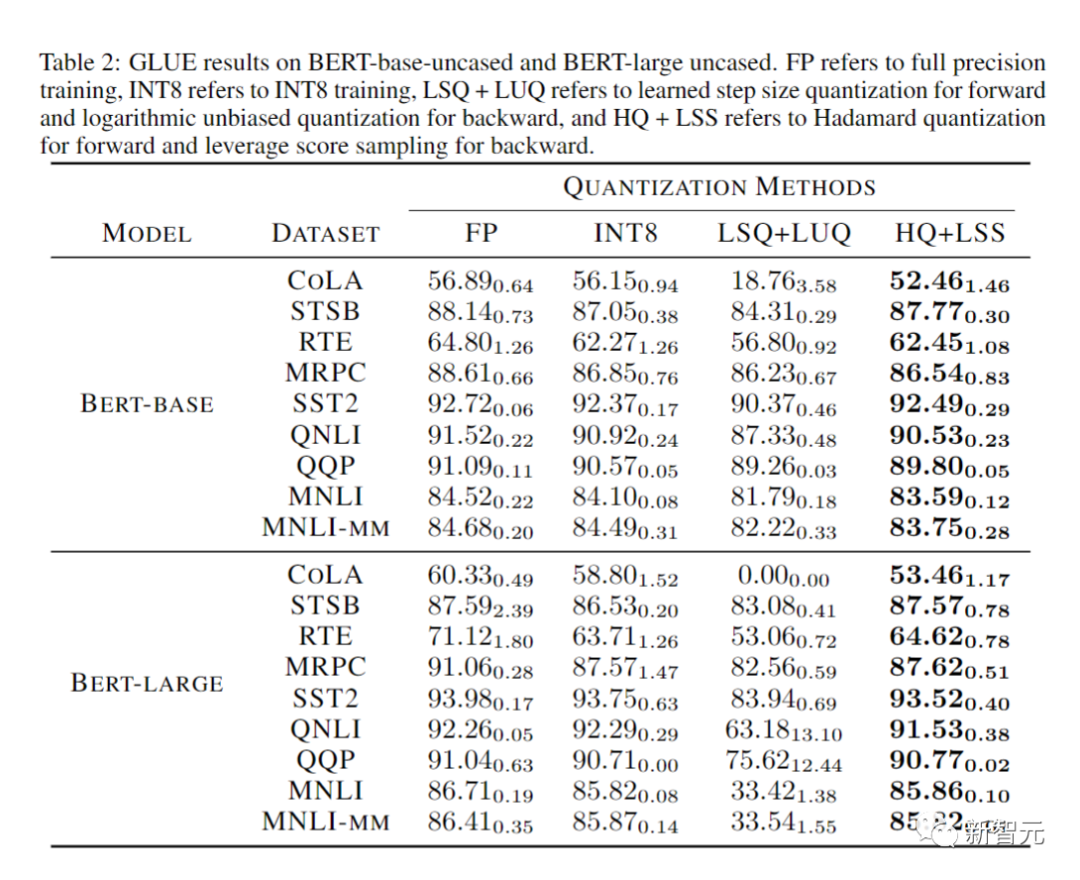
计算和内存效率
最后,研究人员通过评估他们的原型实现,展示了他们的方法加速神经网络训练的潜力。
而且他们的实施还没有完全优化。
研究人员也没有将线性算子与非线性和归一化进行融合。
因此,结果不能完全反映INT4训练算法的潜力。
完全优化的实施需要大量工程,超出了我们论文的讨论范围。
结论
研究人员提出了一种对硬件很友好的Transformer INT4的训练方法。
通过分析Transformer中MM的属性,研究人员提出了HQ和LSS方法来量化激活和梯度,同时保持准确性。
在几个重要任务上,我们的方法与现有的INT4方法表现相当,甚至更好。
研究人员的这些工作可能会扩展到除了Transformers之外的其他MM架构中,例如 MLP-Mixer、图神经网络和循环神经网络网络。
这是他们未来的研究方向。
更广泛的影响:研究人员的算法可以提高效率并减少训练神经网络的能源消耗,这有助于减少深度学习造成的碳排放。
但是,高效的训练算法还可能促进那些,对于人来安全存在隐患的大语言模型和恶意人工智能应用程序的开发。
比如,会被用于虚假内容生成的相关模型和应用。
限制:这项工作的主要限制是它只能加速具有较大规模的矩阵乘法(线性层)的大模型,但不能加速卷积层。
而且,所提出的方法还不能很好地适用于OPT-175B等超大模型。
据我们所知,即使是INT8训练对于这些超大型模型来说仍然是尚待解决的问题。
以上就是清华朱军团队新作:使用4位整数训练Transformer,比FP16快2.2倍,提速35.1%,加速AGI到来!的详细内容,更多请关注其它相关文章!
# 自定义
# 苹果cms分类seo
# 江阴盐城网站优化工作室
# 湖北营销推广定制服务
# 营销推广型网站
# 台山网站优化seo
# 吉林网站制作网站建设
# 洛阳seo管理系统推广
# 大兴seo网站营销推广
# seo方案的目标
# seo全网营销的作用
# AI
# 过程中
# 浮点
# 几个
# 开源
# 他们的
# 后向
# 前向
# 提出了
# 清华
# 算法
相关栏目:
【
企业资讯168 】
【
行业动态20933 】
【
网络营销52431 】
【
网络学院91036 】
【
运营推广7012 】
【
科技资讯60970 】
相关推荐:
IBM将模拟计算用于人工智能,重塑AI计算
可按用户语气自动回复消息,Zoom 推出基于生成式 AI 的新功能
清华系面壁智能开源中文多模态大模型VisCPM :支持对话文图双向生成,吟诗作画能力惊艳
灯塔AI大模型票房预测上线:开源算法不断提升精准度
SnapFusion技术大幅提升AI图像生成速度
Moka发布AI原生HR SaaS产品“Moka Eva”,布局AGI时代
日入400万,第一批AI骗子已上岗
图像生成过程中遭「截胡」:稳定扩散的失败案例受四大因素影响
边喷火边跳踢踏舞,机器狗最新技能爆火全网!网友直呼真·热狗
移远通信率先完成多场5G NTN技术外场验证,为卫星物联网应用落地提速
吴恩达、Hinton最新对话!AI不是随机鹦鹉,共识胜过一切,LeCun双手赞成
2025年贵州省青少年机器人竞赛在安举行
重磅! 捷通华声灵云AICC荣获第二届光合组织AI解决方案大赛二等奖
开创全新虚拟现实体验的Pimax Crystal VR头显
陈根:AI冥想教练为用户提供个性化指导
大语言模型的视觉天赋:GPT也能通过上下文学习解决视觉任务
Meta 发布 Voicebox AI 模型:可生成音频信息,用于 NPC 对话等
AI行业盛会大咖云集!Sam Altam、“AI教父”......一文看懂最新观点
微盟宣布联合腾讯云共建行业大模型:加快激活AI大模型智能应用
组建团队,字节跳动要造机器人?
软银、淡马锡、沙特阿美突击入股,“协作机器人第一股”节卡股份:强敌环伺,持续失血是常态
实践J*a开发,构建高性能的MongoDB数据迁移工具
无需标注数据,「3D理解」进入多模态预训练时代!ULIP系列全面开源,刷新SOTA
微软宣布为 Azure AI 添加男性声线,增强文本转语音功能
管提需求,大模型解决问题:图表处理神器SheetCopilot上线
MetaGPT开源框架爆红 GitHub,达到1.1万星,模拟软件开发流程
游族AI创新院揭牌成立 推进AI赋能游戏业务
人工智能助力精准学习,猿辅导小猿学练机满足学生个性化学习需求
软通动力多项AI创新产品及应用亮相2025世界人工智能大会
杀入生成式AI的亚马逊云科技,能否再次生成未来?
如布科技发布新产品AI口袋学习机S12
V社谈AI制作游戏被ban:为确保开发者有素材所有权
OpenAI限制网络爬虫访问以保护数据免被用于AI模型训练
你大脑中的画面,现在可以高清还原了
Nature发AIGC禁令!投稿中视觉内容使用AI的概不接收
谷歌内部正在测试代号为Genesis的AI新闻写作产品
数字文明尼山对话 | 在东方圣城与AI潮流梦幻联动,看“智慧大脑”让数字山东更美好
【澎湃原动力】人工智能产业协同创新中心:全产业链资源在这里汇聚
创作音乐/音频的Meta开源AI工具AudioCraft,让用户通过文本提示实现
陈根教授:离人形机器人时代还有10年吗?
小米创始人雷军将揭示小米AI在年度演讲中的最新进展
OpenAI首席执行官表态支持欧盟AI监管
Valve 将拒绝采用 AI 生成未知版权内容的游戏上架 Steam
AI大模型产品集体奔赴高考考场,教育赛道的讯飞星火能赢吗?
WHEE网页地址入口
普林斯顿大学推出 Infinigen AI 模型,生成真实自然环境 3D 场景
支持跨语言、人声狗吠互换,仅利用最近邻的简单语音转换模型有多神奇
金融科技行业:2025年十大人工智能趋势预测
调查:过半数艺术家认为 AI 作图无法帮助他们的工作
马斯克反讽人工智能AI炒作:“机器学习”本质就是统计