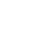写在前面
自动驾驶技术近期因其较低的成本而引起了广泛关注,并且对于提取通用表达式以视觉为中心的自动驾驶技术近期因其较低的成本而引起了广泛关注,并且对于提取通用表达式以视觉为中心的自动驾驶技术近期因其较低的成本而引起了广泛关注,而预训练对于提取通用表达式以视觉为中心的重要。 然而,当前的视觉为中心的预训练通常依赖于2D到3D预训练任务,忽视了自动驾驶作为4D场景理解任务的时序特征。这里通过引入一个基于世界模型的自动驾驶4D表达学习框架"DriveWorld"来解决这一挑战,该框架能够够从多摄像头驱动视频中以时空方式进行预训练。具体来说,提出了一个动态记忆状态空间模型,它由一个动态记忆库模块组成,用于学习时空感知的潜在状态空间模型,并提供全面的场景上下文。此外,还引入了一个静态场景传播模块,用于学习空间感知的潜在场景上下文,并提供全面的场景上下文。此外,还引入了一个静态场景传播模块,用于学习空间感知的潜在场景上下文,并提供全面的场景上下文。这样,DriveWorld在各种自动驾驶任务上获得了令人鼓舞的结果。当使用OpenScene数据集进行预训练时,DriveWorld在各种自动驾驶任务上取得了令人鼓舞的结果。具体来说,DriveWorld在各种自动驾驶任务上取得了令人鼓舞的结果,并提高了mAP达到了7.5%的mAP,线地图中的IoU提高了3.0%,多目标跟踪中的AMOTA提高了5.0%,运动预测中的minADE降低了0.1m,占用预测中的IoU提高了3.0%,规划中的平均L2误差减少少于0.34m。
领域背景
自动驾驶是一项复杂的任务,它依赖于全面的4d场景理解。这要求获取一个精健的时间空表示,能够处理涉及感知、预测和规划的任务。由于自然场景的随机性、环境的部分可观察性以及下游任务的多样性,学习时空表示具有挑战性。预训练在从大量数据中获取通用表示方面起着关键作用,使得能够构建出包含共同知识的基础模型。然而,自动驾驶中时空表示学习的预训练研究仍然相对有限。
我们的目标是利用世界模型来处理以视觉为中心的自动驾驶预训练中的4D表示。世界模型在表示代理环境的时空知识方面表现出色。在强化学习中,DreamerV1、DreamerV2和DreamerV3利用世界模型将代理的经验封装在预测模型中,在预测模型中进行广泛行为学习。MILE利用3D几何作为归纳偏差,直接从专家演示的视频中学习细腻的潜存在空间,在CARLA模拟器中构建世界模型。ContextWM和SWIM利用丰富的野外视频对世界模型进行预训练,以增强下游任务的高效学习。最近,GAIA-1和DriveDreamer构建了生成功能的世界模型,利用视频、文本和动作输入,使用扩散模型创造逼真的驾驶场景。与上述关于世界模型的先进工作不同,本文的方法主要侧重于利用世界模型学习自动驾驶预训练中的4D表示。
驾驶是一项有关本质上涉及到不确定性的斗争。在模糊的自动驾驶场景中,存在两种类 型的不确定性:偶然的不确定性,源于世界的随机性;以及认知不确定性,源于不完美的知识或信息。如何利用过去的经验来预测可能的未来状态,并估计自动驾驶中缺失的世界状态信息仍然是一个未解决的问题。本文探索了通过世界模型进行4D预训练以处理偶然的不确定性和认知不确定性。具体来说,设计了记忆状态空间模型,从两个方面减少自动驾驶中的不确定性。首先,为了处理偶然的不确定性,我们提出了动态记忆库模块,用于学习时空感知的潜在在动态状态。其次,为了缓解认知不确定性,我们提出了静态场景传播模块,用于学习空间感知的潜在静态特征,以提供全面的场景上下文。此外,引入了任务提示(Task Prompt),它利用语义线索作为提示,以自适应地调整特征提取网络,以适应不同的下游驾驶任务。
为了验证提出的4D预训练方法的性能,在nuScenes训练集和最近发布的大规模3D占用率数据集OpenScene上进行了预训练,随后在nuScenes训练集上进行了微调。实验结果表明,与2D ImageNet预训练相比,4D预训练和知识蒸馏算法相比,4D预训练方法具有显著优势。4D预训练算法在以视觉为中心的自动驾驶任务中表现出极大的改进,包括3D检测、多目标跟踪、在线建图、运动预测、占用率预测和规划。
网络结构
DriveWorld的总体框架如下所示,由于自动驾驶严重依赖于传统的理解,方法首先涉及将多摄像头图片转换为4D空间。在所提出的时空建模的记忆状态空间模型中,有两个基本组件:动态记忆库,它学习时间感知的潜存在动态以预测未来状态;以及静态场景传播,它学习空间感知的潜在静态特征以提供全面的场景上下文。这种配置有助于解码器为当前和未来任务感知特征。此外,基于预训练的文本编码器设计了任务prompt,以自适应地为各种任务解耦任务感知特征。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
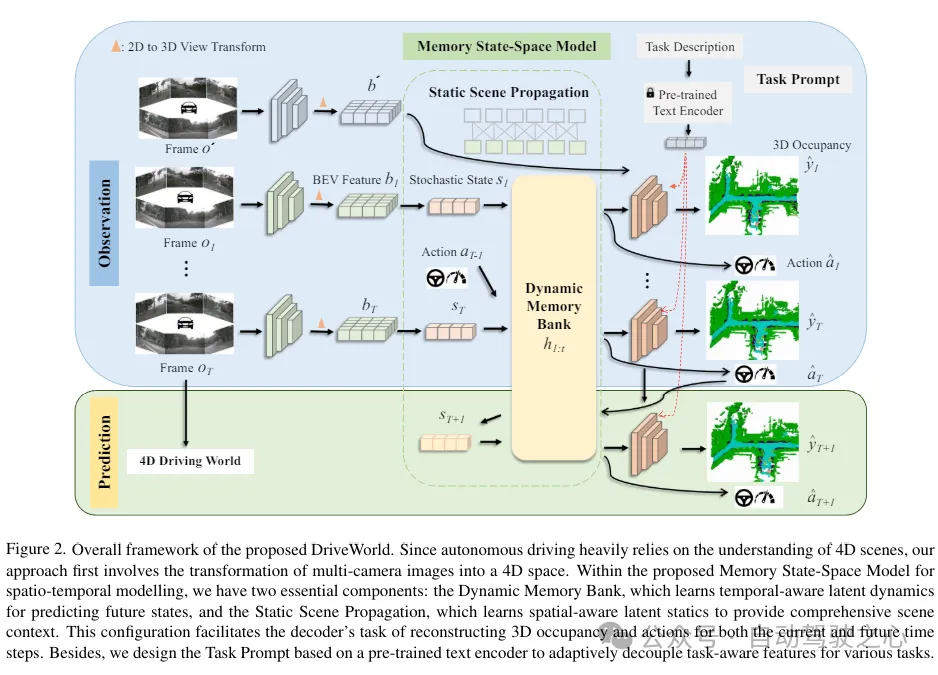
原文提出的记忆状态空间模型(MSSM)的总体架构。MSSM将传入的信息分为两类:时间感知信息和空间感知信息。动态记忆库模块利用运动感知层归一化(MLN)来编码时间感知属性,并与动态更新的记忆库进行信息交互。同时,静态场景传播模块利用BEV特征来表示空间感知的浸泡在静态信息,这些信息直接被传送到解码器。
虽然通过世界模型 设计的预训练任务使得时空表示的学习成为可能,但不同的下游任务侧重于不同的信息。例如,3D检测任务强调当前的空间感知信息,而未来预测任务则优先考虑时序感知信息。过分关注未来的信息,如车辆未来的位置,可能会对3D检测任务产生不利影响。为了解决这个问题,接下来的任务示例驱动的提取了“任务提示”的概念,为不同的头提供特定的线索,以指导它们提取任务感知特征。认识到不同任务之间存在的语义联系,利用大型语言模型来构建这些任务提示。
设计的预训练任务使得时空表示的学习成为可能,但不同的下游任务侧重于不同的信息。例如,3D检测任务强调当前的空间感知信息,而未来预测任务则优先考虑时序感知信息。过分关注未来的信息,如车辆未来的位置,可能会对3D检测任务产生不利影响。为了解决这个问题,接下来的任务示例驱动的提取了“任务提示”的概念,为不同的头提供特定的线索,以指导它们提取任务感知特征。认识到不同任务之间存在的语义联系,利用大型语言模型来构建这些任务提示。
损失函数
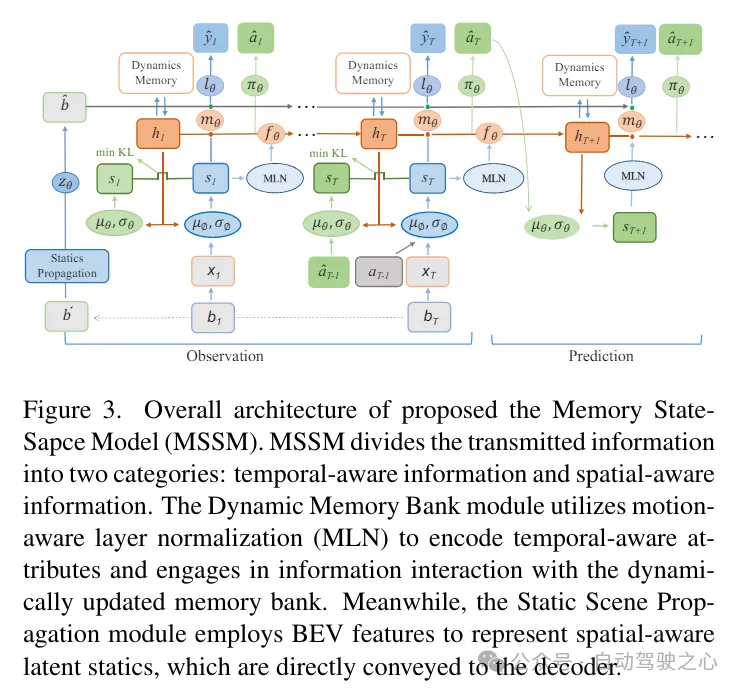
DriveWorld的预训练目标涉及最小化后验和先验状态分布之间的差异(即Kullback-Leibler(KL)散度),以及最小化与过去和未来3D占用,即CrossEntropy损失(CE)和L1损失。这里描述了模型在T个时间步上观察输入,然后预测未来L步的3D占用和动作。DriveWorld的总损失函数是:
 Canva AI
Canva AI
Canva平台AI图片生成工具
 1374
查看详情
1374
查看详情

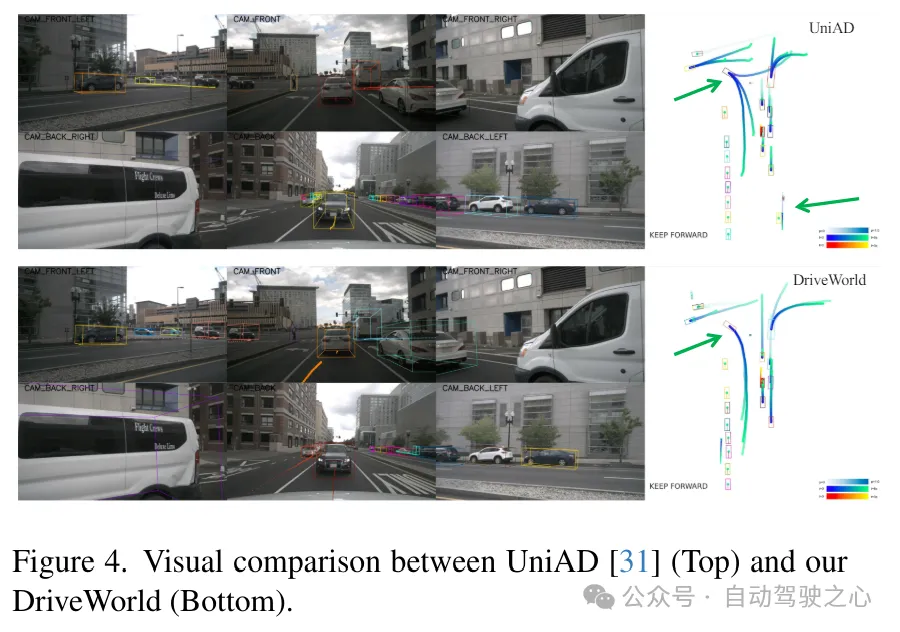
实验对比分析
数据集。在自动驾驶数据集nuScenes 和最大规模的3D占用数据集OpenScene 上进行预训练,并在nuScenes上进行微调。评估设置与UniAD 相同。
预训练。与BEVFormer 和UniAD 一致,使用ResNet101-DCN 作为基础骨干网络。对于3D占用预测,设置了16 × 200 × 200的体素大小。学习率设置为2×10−4。默认情况下,预训练阶段包含24个epoch。
微调。在微调阶段,保留用于生成BEV特征的预训练编码器,并对下游任务进行微调。对于3D检测任务,我们使用了BEVFormer 框架,微调其参数而不冻结编码器,并进行了24个epoch的训练。对于其他自动驾驶任务,我们使用了UniAD 框架,并将我们微调后的BEVFormer权重加载到UniAD中,对所有任务遵循标准的20个epoch的训练协议。对于UniAD,我们遵循其实验设置,这包括在第一阶段训练6个epoch,在第二阶段训练20个epoch。实验使用8个NVIDIA Tesla A100 GPU进行。
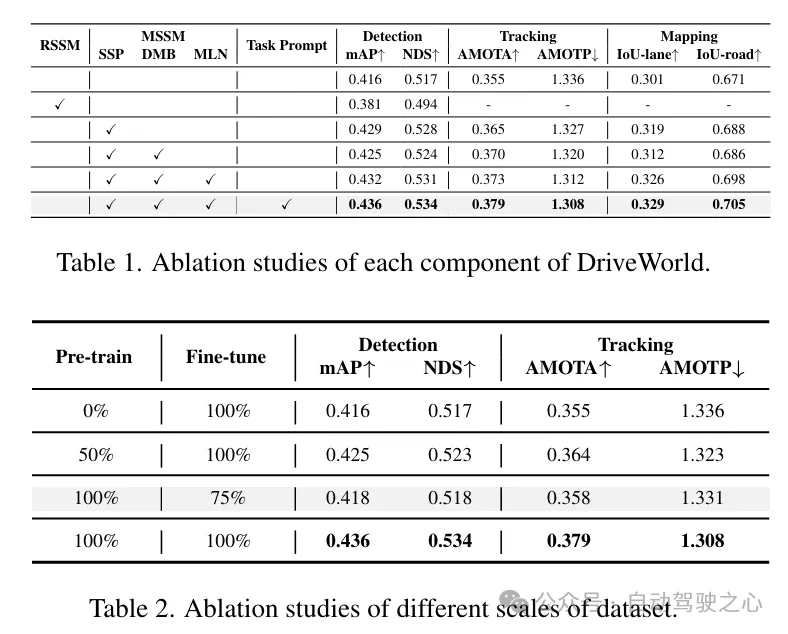
Occ任务和BEV-OD任务上的提升一览:
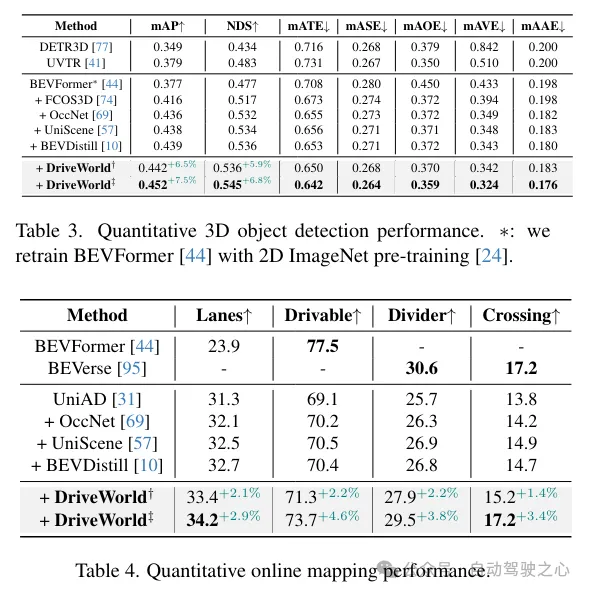
更多目标跟踪和规划任务性能提升一览:
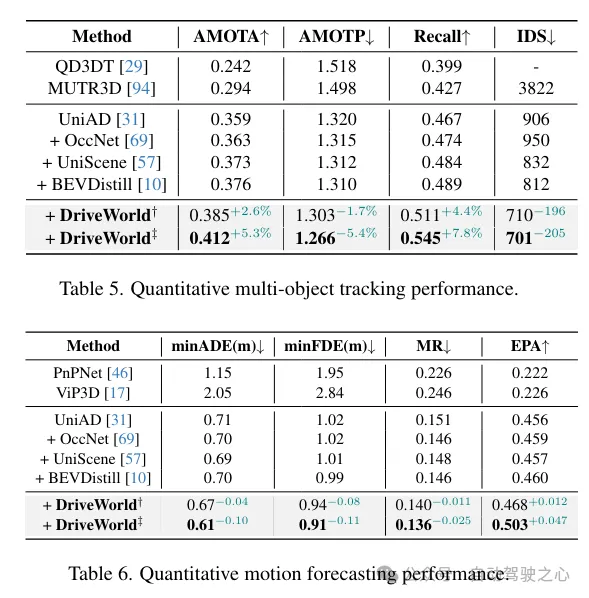
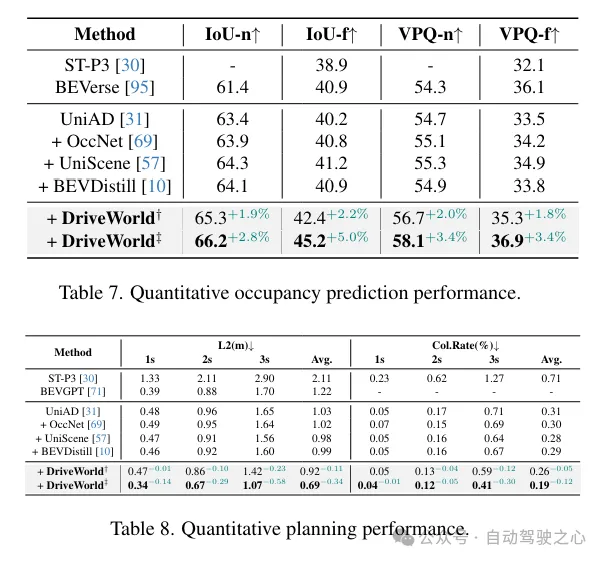
以上就是DriveWorld:一个预训练模型大幅提升检测+地图+跟踪+运动预测+Occ多个任务性能的详细内容,更多请关注其它相关文章!
# 驾驶技术
# 运营推广网站设计流程图
# 湖州塑料薄膜网站建设
# 广州小红书推广优化营销
# 碳水seo
# 怎样优化新网站链接设计
# 惠州网站优化找哪家公司
# 盐城网络营销推广seo
# 尉氏附近网站推广店地址
# 自助网站建设方案书范文
# seo重点学哪些方面
# 近期
# 模型
# 提高了
# 进行了
# 因其
# 较低
# 提出了
# 令人鼓舞
# 未来
# 多个
# 模拟器
# 自动驾驶
相关栏目:
【
企业资讯168 】
【
行业动态20933 】
【
网络营销52431 】
【
网络学院91036 】
【
运营推广7012 】
【
科技资讯60970 】
相关推荐:
腾讯AI首次模拟拼接三星堆文物,工作取得阶段性的成果
联合国秘书长称支持建立全球人工智能监管机构
午报 | 字节跳动要造机器人;东方甄选首次启动自有APP|直播|
联想创投携手12家被投企业MWC展示元宇宙、机器人等技术
2025VR&AR显示技术峰会视频解析: 歌尔光学展示最新一代VR/AR光学模组
7大探索区域打造沉浸式玩乐“元宇宙” 昆明京东MALL未来科技探索官全城招募中
特斯拉 Optimus 人形机器人入驻北美门店,帮助提升汽车销量
RoboNeo什么时候上线
无需照相馆,AI证件照生成软件即将推出
OpenAI CEO 山姆・阿尔特曼呼吁 AI 领域中美应当合作
警惕!AI或致虚假信息泛滥
印象笔记开放旗下“印象 AI”,可一键生成思维导图、写文章等
中国最强AI研究院的大模型为何迟到了
DreamAvatar数字人在哪里下载
从谷歌到亚马逊,科技巨头们的AI痴迷
笔神作文声讨学而思AI大模型 称用“爬虫”技术盗取数据
“风乌”气象大模型科学家团队:用AI预报极端天气未来不是梦!
如何利用物联网技术提高企业生产线智能化水平,提升生产效率
两架海燕号无人机交付中国气象局 助力建设国家级机动气象观测业务
AI赋能艺术 超现实达利奇幻之旅在沪开启
无人机巡检方案是什么,该如何选择适合的巡检方案
苹果推出全新沉浸式 AR 体验应用“Deep Field”
AI 助手 Copilot 上线,微软 Win11 Dev 预览版 Build 23493 发布
XREAL Beam 投屏盒子正式发布:支持“可悬停 AR 空间屏”
MIT开发“PhotoGuard”技术保护图像免遭恶意AI编辑
Meta发布语音AI模型 Voicebox 助虚拟助手与NPC对话
社区里,孩子们体验“机器人竞技”
人工智能即将进入Windows:企业准备好安全策略设置了吗?
世界人工智能大会|“AI领航,共筑未来”高端保险论坛成功举办
即将到来:AI婚纱设计软件实际测试,人工智能即将开创婚纱设计新纪元
周星驰支持的人工智能与 Web3 初创公司 Moonbox 完成 100 万美元融资
OpenAI更新GPT-4等模型,新增API函数调用,价格最高降75%
DragGAN开源三天Star量23k,这又来一个DragDiffusion
如何获得元宇宙的第一个属于自己的空间
Win11 AI 助手 Windows Copilot 被吐槽:套皮的 Edge 浏览器
“痴迷”元宇宙,魔珐科技想做什么?
如何用Transformer BEV克服自动驾驶的极端情况?
WPS AI 官网上线:可申请体验官资格,支持 Windows、安卓端下载
学而思推出AI第一课:基于自研大模型的AIGC课程
时隔 4 年:谷歌更新安卓机器人 LOGO,形象更立体
家电行业观察:AI加持下,全屋智能将成为智能家电未来?
抖音在Android平台获得VR|直播|软件著作权
华为将于 7 月发布面向 AI 大模型的新款存储产品
国内首家,360智脑通过中国信通院可信AIGC大语言模型功能评估
英特尔张宇:边缘计算在整个AI生态系统中扮演重要角色
大模型新品出现井喷,AI产业迎来新时代
500元一张的AI艺术二维码制作,详细教程来了!
AI新风口?首个高质量「文生视频」模型Zeroscope引发开源大战:最低8G显存可跑
北京市元宇宙产业创新中心筹建工作正式启动
谷歌AudioPaLM实现「文本+音频」双模态解决,说听两用大模型