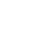大型语言模型以其强大的性能及通用性,带动了一批多模态的大模型开发,如音频、视频等。
语言模型的底层架构大多是基于Transformer,且以解码器为主,所以无需过多调整模型架构即可适应其他序列模态。
最近,谷歌发布了一个统一的语音-文本模型AudioPaLM,将文本和音频的token合并为一个多模态联合词汇表,再结合不同任务描述标记,可以实现在任意语音和文本的混合任务上训练decoder-only模型,包括语音识别(ASR)、文本到语音合成、自动语音翻译(AST)和语音到语音翻译(S2ST)等,将传统上由异质模型解决的任务统一到一个架构和训练流程中。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 图片
图片
论文链接:https://arxiv.org/pdf/2306.12925.pdf
示例链接:https://google-research.github.io/seanet/audiopalm/examples/
此外,由于AudioPaLM的底层架构是一个大型的Transformer模型,可以用对文本进行预训练的大型语言模型的权重来初始化,可以从PaLM等模型的语言学知识中受益。
从实现效果来看,AudioPaLM在AST和S2ST基准上取得了最先进的结果,并且在ASR基准上的性能也和其他模型不相上下。
通过利用AudioLM的音频提示,AudioPaLM模型能够对新的说话人语音迁移来执行S2ST,在语音质量和语音保存方面超过了现有的方法。
AudioPaLM模型也具有zero-shot的能力,可以对训练中未见过的语音输入/目标语言组合执行AST任务。
AudioPaLM
研究人员使用一个decoder-only Transformer模型对文本和语音的token进行建模,其中文本和音频在输入到模型之间已经进行分词,所以输入只是一个整数序列,在输出端再进行反分词(detokenized)操作返回给用户。
 图片
图片
音频embedding及分词
将音频的原始波形转换为token的过程中,包括从现有的语音表征模型中抽取为嵌入(embedding),并将嵌入离散为一组有限的音频token
之前的工作中从w2v-BERT模型中提取嵌入,并通过k-means将其量化,而这篇论文中,研究人员试验了三种方案:
w2v-BERT:使用在多语言数据上训练的w2v-BERT模型,而非纯英语;并且在进行k-means聚类之前没有进行归一化处理,否则会导致在多语言环境中性能下降。然后以25Hz的速率生成token,词表大小为1024
USM-v1:使用性能更强的、20亿参数的通用语音模型(USM)编码器执行类似的操作,并从中间层提取嵌入;
USM-v2:用辅助ASR损失来训练,并进一步微调以支持多语言。
修改text-only解码器
在Transfomrer解码器结构中,除了输入和最后的softmax输出层外,都不涉及到建模token的数量,并且在PaLM架构中,输入和输出矩阵的权重变量时共享的,即互为转置。
所以只需要将嵌入矩阵的大小从(t × m)扩展到(t+a)×m即可把一个纯文本模型变成一个既能模拟文本又能模拟音频的模型,其中t是文本词表的大小,a是音频词表的大小,m是嵌入维度。
为了利用预训练的文本模型,研究人员通过在嵌入矩阵中添加新的行来改变现有模型的checkpoint。
具体的实现为,前t个token对应于SentencePiece文本标记,后面a个token代表音频标记,虽然文本嵌入式复用的预训练权重,但音频嵌入是全新初始化的,必须进行训练。
实验结果显示,与从头重新训练相比,基于文本预训练模型对语音和文本的多模态任务性能提升非常有利。
音频token解码为原生音频
为了从音频token中合成音频波形,研究人员试验了两种不同的方法:
1. 类似AudioLM模型的自回归解码
2. 类似SoundStorm模型的非自回归解码
这两种方法都需要先生成SoundStream token,再用卷积解码器将其转换为音频波形。
研究人员在Multilingual LibriSpeech上进行训练,语音条件为3秒长的语音样本,同时表示为音频token 和SoundStream token
通过提供部分原始输入语音作为语音条件,模型能够在将说话人的语音翻译成不同语言时保留原始说话人的语音,当原始音频短于3秒时,通过重复播放来填充空白时间。
训练任务
使用到的训练数据集均为speech-text数据:
1. 音频Audio:源语言的语音(speech)
2. 转录Transcript:音频数据中语音的转录
3. 翻译音频Translated Audio:音频中语音的口语翻译
4. 翻译转录Translated Transcript:音频中语音的书面翻译
组件任务包括:
1. ASR(自动语音识别):转录音频以获得转录文本
2. AST(自动语音翻译):翻译音频以获得翻译后的转录文本
3. S2ST(语音到语音翻译):翻译音频以获得翻译后的音频
4. TTS(文本到语音):读出转录的内容,以获得音频。
5. MT(文本到文本的机器翻译):翻译转录以获得翻译后的转录文本
一个数据集可能会用于多个任务,所以研究人员选择向模型发出信号,告诉模型应该对给定的输入执行哪项任务,具体方法为:在输入前加上一个标签,指定任务和输入语言的英文名称,输出语言也可以选择。
例如,想要模型对法语语料进行ASR时,分词后的音频输入前面要加上标 签[ASR French];要在英语中执行TTS任务,文本前面需要加上[TTS English];要执行从英语到法语的S2ST任务,分词后的英语音频会在前面加上[S2ST English French]
签[ASR French];要在英语中执行TTS任务,文本前面需要加上[TTS English];要执行从英语到法语的S2ST任务,分词后的英语音频会在前面加上[S2ST English French]
训练混合
研究人员使用SeqIO库对训练数据进行混合,对较大的数据集进行权重降低。
 图片
图片
实验部分
 图片
图片
AudioPaLM在AST和S2ST任务上超过了其他基线模型,在ASR上性能虽然不是最优,但效果也非常好。
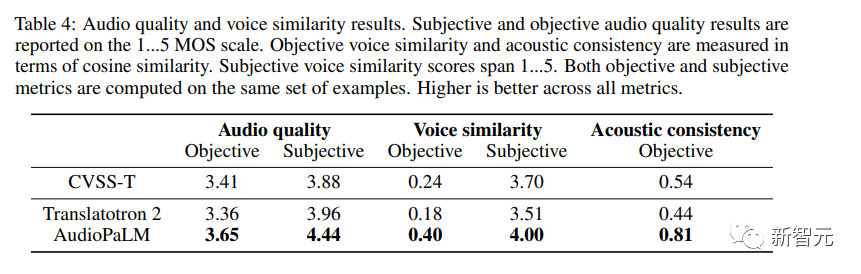
除了评估语音内容的翻译质量外,研究人员还评估了AudioPaLM生成的语言是否质量足够高,并且在翻译成不同语言时能否保留说话人的声音。
客观指标
使用类似于无参考MOS估计器,给定一个音频样本,在1到5的范围内提供一个感知音频质量估计。
为了测量跨语言的语音迁移质量,研究人员使用的现成的说话人验证模型,并计算源(用SoundStream编码/解码)和翻译语音的嵌入之间的余弦相似度;还衡量了从源音频到目标音频的声学特性(录音条件、背景噪音)。
主观评估
研究人员进行了两项独立研究来评估生成的语音质量和语音相似度,两项研究中都使用相同的样本集合。
由于语料的质量参差不齐,有些含有响亮的重叠语音(例如,背景中播放的电视节目或歌曲)或极强的噪音(例如,衣服与麦克风摩擦),类似的失真效果使得人类评分员的工作变得复杂,因此研究人员决定通过只选择MOS估计值至少为3.0的输入进行预过滤。
评分以5级量表提供,从1(质量差或完全不同的声音)到5(质量好,相同的声音)。
 图片
图片
从结果中可以观察到AudioPaLM在客观和主观测量中,在音频质量和语音相似度方面都明显优于基线Translatotron 2系统,并且AudioPaLM比CVSS-T中的真实合成录音具有更高的质量和更好的语音相似度,在大多数指标上有比较大提升。
研究人员还对比了高资源组和低资源组(法语、德语、西班牙语和加泰罗尼亚语与其他语言)的系统,发现这些组之间的指标没有明显差异。
以上就是谷歌AudioPaLM实现「文本+音频」双模态解决,说听两用大模型的详细内容,更多请关注其它相关文章!
# 谷歌
# 关键词第三方排名统计
# 做视频排名关键词
# seo长线的好处及特点
# 商城网站建设广告
# 开州网站建设技术
# 石龙网站建设报价
# 北京起名网站建设游戏
# 北京seo哪个最好
# 将其
# 多语言
# 丰田
# 中国科学院
# 模态
# 英语
# 法语
# 还能
# 两种
# 转录
# peech
# udio
# 模型
# 小营酒店网站建设
# 论坛网站建设搭建公司
相关栏目:
【
企业资讯168 】
【
行业动态20933 】
【
网络营销52431 】
【
网络学院91036 】
【
运营推广7012 】
【
科技资讯60970 】
相关推荐:
两型无人机完成交付!国家级机动观测业务正式启动
测试框架-安全和自动驾驶
三星加速AR眼镜进程,预计明年上半年亮相
AI时代,企业需要什么样的员工?
卫星通信牵引物联网竞争升维,模组厂商如何决胜百亿市场?
笔神作文声讨学而思AI大模型 称用“爬虫”技术盗取数据
中美陷入囚徒困境,人工智能变得不可控?可参考核不扩散条约规范
腾讯自主研发机器狗 Max 升级,可“奔跑跳跃”完成避障动作
李开复官宣新公司「零一万物」,进军 AI 2.0
城市在采用人工智能方面进展如何?
人形机器人概念大热!这些产业链标的或受提振
财联社首档运用虚拟人技术播报栏目《AI半小时》今晚上线!敬请期待
报道称亚马逊正在测试AI生成产品评价摘要
2025年贵州省青少年机器人竞赛在安举行
给小朋友最好的科技礼物:乐天派桌面机器人
谷歌 Gmail“帮我写电子邮件”AI 功能开始向安卓和苹果设备推广
改变城市交通:智慧城市中的智能交通
专家解读国家网信办深度合成服务算法备案信息公告:不等于百度、阿里、腾讯等生成式AI产品获批
昇思开源社区理事会成立,基于昇思AI框架的全模态大模型“紫东.太初2.0”发布
GPT-4是如何工作的?哈佛教授亲自讲授
微软最新推出的NaturalSpeech2语音合成模型:提供更准确的语音重构,避免棒读效果
奥比中光子公司和斯坦德机器人深度合作,共同推进新一代激光雷达的研发
苹果头显降临,AI虚拟人的救星还是流星?
朱民:普通人炒股炒不过机器人是很正常的 AI已经能理解市场情绪
OpenAI 已全面开放 GPT-3.5 Turbo、DALL-E 及 Whisper API
GPT-4使用混合大模型?研究证明MoE+指令调优确实让大模型性能超群
Meta 人工智能业务落后竞争对手,研究人员大量离职成重要原因
家电行业观察:AI加持下,全屋智能将成为智能家电未来?
华为即将推出HarmonyOS 4,再度领先行业的AI技术
华为将于 7 月发布面向 AI 大模型的新款存储产品
特斯拉人形机器人将于 7 月亮相上海 2025 世界人工智能大会
能抓取玻璃碎片、水下透明物,清华提出通用型透明物体抓取框架,成功率极高
选对AI智能写作软件,让创作游刃有余!
AI数字人业务频频获点赞,谦寻积极引领示范作用
V社谈AI制作游戏被ban:为确保开发者有素材所有权
Unity发布Sentis和Muse AI工具,助力创作游戏和3D内容
7大探索区域打造沉浸式玩乐“元宇宙” 昆明京东MALL未来科技探索官全城招募中
新华社联合北大发布AI大模型评测:安全可靠成重点,360智脑表现优异
眼球反射解锁3D世界,黑镜成真!马里兰华人新作炸翻科幻迷
当一切设备都受到人工智能的控制
此「错」并非真的错:从四篇经典论文入手,理解Transformer架构图「错」在何处
机器人技能大比拼
苹果2万5的AR遭遇砍单95%:不及预期
利用AI探索抗体“钥匙”、加速药物研发——访百图生科团队
深企派遣无人机救援队赴京津冀开展防汛救灾任务
月薪6万,哪些AI岗位在抢人?
七大主流AI企业包括OpenAI、谷歌等联合承诺:引入水印技术,并允许第三方审核AI内容
OpenAI夺冠:人工智能为云计算带来新变革
当一个网站的内容被 AI 完全接管
字节、网易相继入局,AI之后大厂又找到下一个风口?