本文介绍用PaddlePaddle2构建长短期记忆网络模型。先讲引入时间步的单隐藏层、多隐藏层模型,说明隐藏层输出与输入及前一时间步输出的关系;再阐述长短期记忆网络通过输入门、遗忘门、输出门处理长跨度时间依赖。最后用该模型对IMDB电影评论做情感预测,经10轮训练,测试集准确率约84% - 85%。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

PaddlePaddle2构建长短期记忆网络模型
作者:陆平
现实世界中,有一类问题是需要考虑时间顺序,比如,文本分类、机器翻译、语音识别、证券价格走势分析、宏观经济指标预测等。这类问题在推断下一个时间点的预测值时候,不仅需要依赖当前时间点的输入,还要依赖过去时间点的情况。利用长短期记忆网络模型可以用来处理具有长跨度时间依赖的问题。为了更易于理解,采用以下循序渐进的方式:首先需要理解如何在单隐藏层模型中引入时间步,其次是要理解如何构建引入时间步的多隐藏层模型,最后理解长短期记忆网络模型。
1. 引入时间步的单隐藏层模型
在解析模型之前,我们首先回顾一下多层感知机模型。多层感知机模型至少拥有1个隐藏层。给定一个大小为n的批量样本,特征数量为d,输入表示为X∈Rn×d,批量化的输入特征与权重相乘,之后用函数σ进行激活,隐藏层输出H∈Rn×h为:
H=σ(Xwxh+bh)
其中,wxh∈Rd×h,bh∈R1×h.如果是分类问题,设最终的类别数为c,接下来,把经过隐藏层激活的输出值进行线性转化,得到输出层的值。
O=Hwo+bo
其中,O∈Rn×c,wo∈Rh×c,bo∈R1×c.
最后,进行SoftMax运算,把输出值转变成概率分布。
现在我们在模型中引入时间步概念。时间步t的隐藏层输出由时间步t-1的隐藏层输出与时间步t的输入共同决定。
设时间步t的输入为Xt∈Rn×d,时间步t-1的隐藏层输出为Ht−1∈Rn×h,时间步t的隐藏层输出为:
Ht=σ(Xtwxh+Ht−1whh+bh)
其中,wxh∈Rd×h,whh∈Rh×h,bh∈R1×h.
接下来与多层感知机类似,把经过时间步t的隐藏层输出值进行线性转化,最后接SoftMax运算得到输出类别的概率。
2. 引入时间步的多隐藏层模型
下面我们来看拥有2个隐藏层的考虑时间步的多隐藏层模型。仍以构建多层感知机来理解,构造一个具有2个隐藏层的多层感知机。给定一个大小为n的批量样本,特征数量为d,输入表示为X∈Rn×d,批量化的输入特征与权重相乘,之后用函数σ进行激活,第一个隐藏层h1输出H(1)∈Rn×h1为:
H(1)=σ(Xwx,h1+bh1)
其中,wx,h1∈Rd×h1,bh1∈R1×h1。 之后,接第二个隐藏层h2,该层的输出H(2)∈Rn×h2为:
H(2)=σ(H(1)wh1,h2+bh2)
其中,wh1,h2∈Rh1×h2,bh2∈R1×h2。 设最终的类别数为c,接下来,把经过隐藏层激活的输出值进行线性转化,得到输出层的值。
O=H(2)wh2,o+bo
其中,O∈Rn×c,wh2,o∈Rh2×c,bo∈R1×c.
通过SoftMax运算,把输出值转变成概率分布。
参考多层感知机的构建方法,我们构造一个具有2个隐藏层的模型。 设时间步t的输入为Xt∈Rn×d,时间步t-1的隐藏层h1输出为Ht−11∈Rn×h1,时间步t的隐藏层h1输出为:
Ht(1)=σ(Xtwx,h1+Ht−1(1)wh1,h1+bh1)
其中,wx,h1∈Rd×h1,wh1,h1∈Rh1×h1,bh∈R1×h1.
 简小派
简小派
简小派是一款AI原生求职工具,通过简历优化、岗位匹配、项目生成、模拟面试与智能投递,全链路提升求职成功率,帮助普通人更快拿到更好的 offer。
 123
查看详情
123
查看详情

接下来进入第二个隐藏层,时间步t的隐藏层h2输出Ht(2)∈Rn×h2为:
Ht(2)=σ(Ht(1)wh1,h2+Ht−1(2)wh2,h2+bh2)
其中,wh1,h2∈Rh1×h2,wh2,h2∈Rh2×h2,bh2∈R1×h2.
接下来,把经过第二个隐藏层的输出值进行线性转化,得到输出层的值。
Ot=Ht(2)wh2,o+bo
其中,Ot∈Rn×c,wh2,0∈Rh2×c,b0∈R1×c。最后通过SoftMax运算,把输出值转变成概率分布。
3. 长短期记忆网络
为了让模型具有处理具有长跨度时间依赖能力,长短期记忆网络模型通过输入门、遗忘门与输出门来选择性记忆时序信息。
长短期记忆网络模型的整体结构如下:
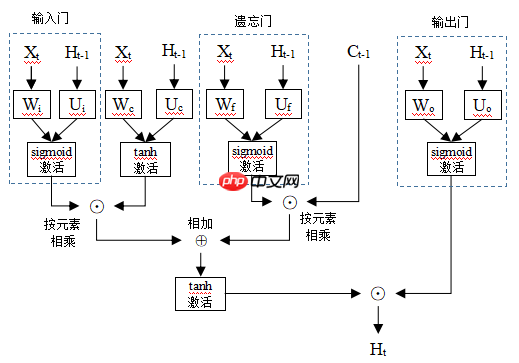
输入门(input gate)是用来衡量当前时间步输入的重要程度。给定一个大小为n的批量样本,输入特征数量为d,输出特征数量为q。时间步t的输入表示为Xt∈Rn×d,它与权重Wi∈Rd×q相乘,再加上时间步t-1的输出特征Ht−1∈Rn×q与权重Ui∈Rq×q乘积,接sigmoid函数激活,得到输出it∈Rn×q为:
it=σ(XtWi+Ht−1Ui)
遗忘门(foget gate)是用来衡量上一个时间步的单元状态值Ct−1∈Rn×q被记忆的程度。时间步t的输入Xt∈Rn×d与权重Wf∈Rd×q相乘,时间步t-1的输出特征Ht−1∈Rn×q与权重Uf∈Rq×q乘积,这两者相加后用sigmoid函数激活,得到输出ft∈Rn×q:
ft=σ(XtWf+Ht−1Uf)
输出门(output gate)是用来衡量单元状态值Ct∈Rn×q的暴露程度。时间步t的输入Xt∈Rn×d与权重Wo∈Rd×q相乘,时间步t-1的输出特征Ht−1∈Rn×q与权重Uo∈Rq×q乘积,这两者相加后用sigmoid函数激活,得到输出Ot∈Rn×q:
Ot=σ(XtWo+Ht−1Uo)
假设新的单元状态值是当前时间步输入信息与上一时间步输出的某种融合。时间步t的输入Xt∈Rn×d与权重Wc∈Rd×q相乘,时间步t-1的输出特征Ht−1∈Rn×q与权重Uc∈Rq×q乘积,这两者相加后用tanh函数激活。用以下式子表示:
C~t=tanh(XtWc+Ht−1Uc)
通过上面三个门,实现对时序信息进行选择性记忆与遗忘。时间步t的单元状态值Ct是以下两者的结合:一是上一时间步单元状态值Ct−1与记忆度ft按元素相乘,用来衡量被留下来的记忆。二是新的单元状态值C~t与重要度it按元素相乘,用来衡量新信息的重要性。
Ct=ft⨀Ct−1+it⨀C~t
最后,用输出门控制单元状态值Ct的暴露程度,得到输出Ht∈Rn×q,表示如下:
Ht=Ot⨀tanhCt
4. 基于LSTM模型的电影评论情感倾向预测
基于PaddlePaddle2.0基础API构建LSTM模型,利用互联网电影资料库Imdb数据来进行电影评论情感倾向预测。
In [1]import numpy as npimport paddle#准备数据#加载IMDB数据imdb_train = paddle.text.datasets.Imdb(mode='train') #训练数据集imdb_test = paddle.text.datasets.Imdb(mode='test') #测试数据集#获取字典word_dict = imdb_train.word_idx#在字典中增加一个<pad>字符串word_dict['<pad>'] = len(word_dict)#参数设定vocab_size = len(word_dict)
embedding_size = 256hidden_size = 256n_layers = 2dropout = 0.5seq_len = 200batch_size = 64epochs = 10pad_id = word_dict['<pad>']#每个样本的单词数量不一样,用Padding使得每个样本输入大小为seq_lendef padding(dataset):
padded_sents = []
labels = [] for batch_id, data in enumerate(dataset):
sent, label = data[0].astype('int64'), data[1].astype('int64')
padded_sent = np.concatenate([sent[:seq_len], [pad_id] * (seq_len - len(sent))]).astype('int64')
padded_sents.append(padded_sent)
labels.append(label) return np.array(padded_sents), np.array(labels)
train_x, train_y = padding(imdb_train)
test_x, test_y = padding(imdb_test)
class IMDBDataset(paddle.io.Dataset):
def __init__(self, sents, labels):
self.sents = sents
self.labels = labels def __getitem__(self, index):
data = self.sents[index]
label = self.labels[index] return data, label def __len__(self):
return len(self.sents)
train_dataset = IMDBDataset(train_x, train_y)
test_dataset = IMDBDataset(test_x, test_y)
train_loader = paddle.io.DataLoader(train_dataset, return_list=True, shuffle=True, batch_size=batch_size, drop_last=True)
test_loader = paddle.io.DataLoader(test_dataset, return_list=True, shuffle=True, batch_size=batch_size, drop_last=True)#构建模型class LSTM(paddle.nn.Layer):
def __init__(self):
super(LSTM, self).__init__()
self.embedding = paddle.nn.Embedding(vocab_size, embedding_size)
self.lstm_layer = paddle.nn.LSTM(embedding_size,
hidden_size,
num_layers=n_layers,
direction='bidirectional',
dropout=dropout)
self.linear = paddle.nn.Linear(in_features=hidden_size * 2, out_features=2)
self.dropout = paddle.nn.Dropout(dropout)
def forward(self, text):
#输入text形状大小为[batch_size, seq_len]
embedded = self.dropout(self.embedding(text)) #embedded形状大小为[batch_size, seq_len, embedding_size]
output, (hidden, cell) = self.lstm_layer(embedded) #output形状大小为[batch_size,seq_len,num_directions * hidden_size]
#hidden形状大小为[num_layers * num_directions, batch_size, hidden_size]
#把前向的hidden与后向的hidden合并在一起
hidden = paddle.concat((hidden[-2,:,:], hidden[-1,:,:]), axis = 1)
hidden = self.dropout(hidden) #hidden形状大小为[batch_size, hidden_size * num_directions]
return self.linear(hidden)#以下使用PaddlePaddle2.0高层API进行训练与评估#封装模型model = paddle.Model(LSTM()) #用Model封装lstm模型#配置模型优化器、损失函数、评估函数model.prepare(paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())#模型训练与评估model.fit(train_loader,
test_loader,
epochs=epochs,
batch_size=batch_size,
verbose=1)Cache file /home/aistudio/.cache/paddle/dataset/imdb/imdb%2FaclImdb_v1.tar.gz not found, downloading https://dataset.bj.bcebos.com/imdb%2FaclImdb_v1.tar.gz Begin to download Download finished /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/distributed/parallel.py:119: UserWarning: Currently not a parallel execution environment, `paddle.distributed.init_parallel_env` will not do anything. "Currently not a parallel execution environment, `paddle.distributed.init_parallel_env` will not do anything." /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working return (isinstance(seq, collections.Sequence) and
The loss value printed in the log is the current step, and the metric is the *erage value of previous step. Epoch 1/10 step 390/390 [==============================] - loss: 0.5087 - acc: 0.6604 - 59ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the *erage value of previous step. step 390/390 [==============================] - loss: 0.5934 - acc: 0.7306 - 20ms/step Eval samples: 24960 Epoch 2/10 step 390/390 [==============================] - loss: 0.5487 - acc: 0.7938 - 59ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the *erage value of previous step. step 390/390 [==============================] - loss: 0.4090 - acc: 0.7619 - 20ms/step Eval samples: 24960 Epoch 3/10 step 390/390 [==============================] - loss: 0.3800 - acc: 0.8056 - 59ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the *erage value of previous step. step 390/390 [==============================] - loss: 0.4242 - acc: 0.8118 - 20ms/step Eval samples: 24960 Epoch 4/10 step 390/390 [==============================] - loss: 0.3291 - acc: 0.8685 - 59ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the *erage value of previous step. step 390/390 [==============================] - loss: 0.3761 - acc: 0.8407 - 20ms/step Eval samples: 24960 Epoch 5/10 step 390/390 [==============================] - loss: 0.3086 - acc: 0.8935 - 59ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the *erage value of previous step. step 390/390 [==============================] - loss: 0.2944 - acc: 0.8450 - 20ms/step Eval samples: 24960 Epoch 6/10 step 390/390 [==============================] - loss: 0.3261 - acc: 0.9089 - 59ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the *erage value of previous step. step 390/390 [==============================] - loss: 0.2982 - acc: 0.8532 - 20ms/step Eval samples: 24960 Epoch 7/10 step 390/390 [==============================] - loss: 0.1245 - acc: 0.9227 - 58ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the *erage value of previous step. step 390/390 [==============================] - loss: 0.5826 - acc: 0.8406 - 20ms/step Eval samples: 24960 Epoch 8/10 step 390/390 [==============================] - loss: 0.2069 - acc: 0.9365 - 59ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the *erage value of previous step. step 390/390 [==============================] - loss: 0.4760 - acc: 0.8495 - 20ms/step Eval samples: 24960 Epoch 9/10 step 390/390 [==============================] - loss: 0.1122 - acc: 0.9460 - 59ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the *erage value of previous step. step 390/390 [==============================] - loss: 0.3009 - acc: 0.8424 - 20ms/step Eval samples: 24960 Epoch 10/10 step 390/390 [==============================] - loss: 0.1645 - acc: 0.9540 - 59ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the *erage value of previous step. step 390/390 [==============================] - loss: 0.6611 - acc: 0.8377 - 20ms/step Eval samples: 24960代码解释
经过10轮epoch训练,模型在测试数据集上的准确率大约为84%至85%。
以上就是基于PaddlePaddle2.0-构建长短期记忆网络的详细内容,更多请关注其它相关文章!
# 是用来
# 网络营销策划推广衣服
# 知乎营销推广方案设计
# seo推广文案好写吗
# 昆明seo推广行情
# 地产微信营销推广文案
# 四川营销推广哪个好
# 外贸营销推广公司推荐
# 西藏抖音seo推荐
# 专利搜索网站建设
# 安徽seo优化格式化
# 官网
# python
# 门控
# 上一
# 这两者
# 转变成
# 第二个
# 中文网
# 量为
# 一言
# type
# udio
# ai
相关栏目:
【
企业资讯168 】
【
行业动态20933 】
【
网络营销52431 】
【
网络学院91036 】
【
运营推广7012 】
【
科技资讯60970 】
相关推荐:
谷歌推出新 AI 工具 Imagen Editor,一句话对图片二次创作
“五年内人类程序员将消失”预言引争议,AI真的那么强大了吗?
新闻传闻:迪士尼可能采用人工智能来控制电影制作成本
2025 WAIC|美团无人机发布第四代新机型
华为小艺AI助手将实现强大的大模型能力
优化系统韧性:故障恢复与监控在RabbitMQ中的应用
AI生成会议纪要 百度如流升级推出超级助手、智能编码等功能
微幼科技推出全自动晨检机器人,助力幼儿园校园健康检测
统信深度deepin成立 AI SIG 社区,共同提升 Linux 下 AI 体验
严打“黑飞”,无人机检测反制设备护航大运会净空安全
此「错」并非真的错:从四篇经典论文入手,理解Transformer架构图「错」在何处
微盟宣布联合腾讯云共建行业大模型:加快激活AI大模型智能应用
普林斯顿大学推出 Infinigen AI 模型,生成真实自然环境 3D 场景
《自然》杂志拒绝刊登人工智能生成的图片和视频
Databricks 发布大数据分析平台 Spark 用 AI 模型 SDK:一键生成 SQL 及 FySpark 语言图表代码
MiracleVision视觉大模型功能介绍
特斯拉首发人形机器人“擎天柱”亮相世界人工智能大会
探展WAIC | 第四范式“式说”聚焦toB大模型,布局生成式AI重构企业软件
人工智能在重症监护室的未来
CharacterAI - 也许会成为会话人工智能的未来
WPS AI 官网上线:可申请体验官资格,支持 Windows、安卓端下载
当一切设备都受到人工智能的控制
上新7款产品,美图继续“蹭”AI
无人机巡检方案是什么,该如何选择适合的巡检方案
谷歌新安卓机器人logo曝光:头更大了
微软大牛加入ZOOM,AI人才大战打响
微软在 Bing 和 Edge 浏览器中拓展网购服务,帮用户选购心仪产品
Adobe旗下Illustrator引入生成式AI工具Firefly
B站内测 AI 搜索功能,输入“?”即可体验
“技术+实践+生态”三箭齐发,京东方抢占物联网高地
Meta 人工智能业务落后竞争对手,研究人员大量离职成重要原因
小米又拿下国际比赛第一:AI翻译立功
美图设计室2.0使用教程
人工智能改变网络安全和用户体验的三种方式
第四范式“式说”大模型入选《2025年通用人工智能创新应用案例集》
Unity 内测 Safe Voice 服务,利用 AI 自动识别玩家不当聊天内容
速途网络成立“人工智能专家委员会”5位中美博士加盟
电力人工智能数据集目录首次发布
25个AI智能体源码现已公开,灵感来自斯坦福的「虚拟小镇」和《西部世界》
亲身体验鸿蒙4:AI大模型带来的便利,告别单纯的旁观者状态
谷歌StyleDrop在可控性上卷翻MidJourney,前GitHub CTO用AI颠覆编程
《共同的演化》展览启幕,重新思考人类与人工智能关系
【原创】奥比中光:与英伟达合作开发的3D开发套件正式发布 连接英伟达AI应用生态
0代码微调大模型火了,只需5步,成本低至150块
自然语言生成在智能家居设备中的应用
杀入生成式AI的亚马逊云科技,能否再次生成未来?
昌吉市利用无人机实现全天候河道动态巡检
AI大举入侵内容行业,哪些上市*及动漫公司进行了布局?
70年前他本想逃避考试,却影响了整个互联网
AI+游戏首度大范围公布实际应用成果,AI全面来临还有多远?